第四正規化・第五正規化・ボイスコッド正規化がややこしいので、備忘録として自分なりにまとめてみた(データベーススペシャリストの勉強)
第一正規化~第三正規化までは、わりと詳しく説明されている場合が多いのですが
第四正規化・第五正規化・ボイスコッド正規化は、実務であまり使われないせいか同じ説明だったり分かりづらかったので
自分でまとめてみました。
分かりやすくするために、結婚相談所サイトをテーマにしてみましょう。
第四正規形
こういったデート予定表があったとして
| 本人(A) | 相手(B) | デート場所(C) |
|---|---|---|
| Xさん | Aさん | 横浜 |
| Xさん | Bさん | 横浜 |
| Xさん | Cさん | 横浜 |
| Yさん | Aさん | 川崎 |
| Yさん | Bさん | 川崎 |
| Zさん | Aさん | 品川 |
このままだと何が問題かと言うと、全てがキー属性(第三正規形)なので、全部の情報が揃わないと登録が出来ません。
例その1)XさんとAさんがデートすると決めても、デート場所が未定ではレコード挿入できない。
例その2)Xさんがデート場所を横浜と決めても、相手が決まるまではレコード挿入できない。(現実的にはコレは普通だけどDB的に出来ないって事ね)
これを第四正規化すると、独立してレコード挿入できるようになります。
また、どちらかを削除しても、片方のデータは残ります。
デート相手表
| 本人(A) | 相手(B) |
|---|---|
| Xさん | Aさん |
| Xさん | Bさん |
| Xさん | Cさん |
| Yさん | Aさん |
| Yさん | Bさん |
| Zさん | Aさん |
デート場所表
| 本人(A) | デート場所(C) |
|---|---|
| Xさん | 横浜 |
| Yさん | 川崎 |
| Zさん | 品川 |
この場合の第四正規化(自明ではない多値従属性を排除する)は、「本人」→「デート場所」が外出しされた事です(元の表だと、同じ情報が重複している)
A→→B|C
から
A→→B
A→→C
に分解した形となります
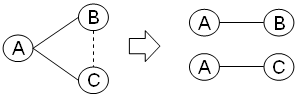
ちなみにビジネスルールとして、「本人(A)」が「デート場所(C)」を決めるルールです(「相手(B)」は連れて行かれるイメージ)
第五正規形
婚活イベント的な何かを管理する表があったとしましょう。
参加イベントのスケジュール表
| 参加者(A) | 会場(B) | イベント名(C) |
|---|---|---|
| Xさん | 横浜 | 30代限定 |
| Xさん | 横浜 | 料理合コン |
| Xさん | 横浜 | イチゴ狩りツアー |
| Yさん | 川崎 | 街コン |
| Yさん | 川崎 | 30代限定 |
| Zさん | 品川 | 年収一千万以上限定 |
これを第五正規化すると、以下のようになります
参加イベント表
| 参加者(A) | イベント名(C) |
|---|---|
| Xさん | 30代限定 |
| Xさん | 料理合コン |
| Xさん | イチゴ狩りツアー |
| Yさん | 街コン |
| Yさん | 30代限定 |
| Zさん | 年収一千万以上限定 |
イベント場所表
| 会場(B) | イベント名(C) |
|---|---|
| 横浜 | 30代限定 |
| 横浜 | 料理合コン |
| 横浜 | イチゴ狩りツアー |
| 川崎 | 街コン |
| 川崎 | 30代限定 |
| 品川 | 年収一千万以上限定 |
参加会場表
| 参加者(A) | 会場(B) |
|---|---|
| Xさん | 横浜 |
| Xさん | 横浜 |
| Xさん | 横浜 |
| Yさん | 川崎 |
| Yさん | 川崎 |
| Zさん | 品川 |
第四正規形との違いは、先ほどの例だと、相手(B)とデート場所(C)は関係なかったのですが、今回は全て(参加者(A), 会場(B), イベント名(C))関係しあっているため、(A,B)(B, C)(A, C)に分解されました。
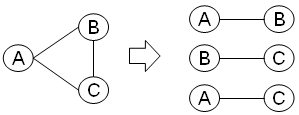
元のテーブルのままだと困る事(全ての情報が決定しないとレコード挿入できない)
例その1)参加者が決まらないと、そもそもイベントが立てられない
例その2)Xさんが30代限定イベントに参加すると決めても、会場を決定しないとダメ
例その3)Xさんが横浜会場に参加すると決めても、イベントを決定しないとダメ
(普通は会場とイベントはセットなので、あんまり困らないと思うが、あくまでDBの例という事で…。)
ボイスコッド正規形
これはわりと簡単
非キー属性が主キーに完全従属している事(主キー以外に関数従属性があってはダメ!)
会員マスタ表
| ID(A) | メールアドレス(B) | 名前(C) |
|---|---|---|
| 1 | a@tekito.com | Aさん |
| 2 | b@tekito.com | Bさん |
| 3 | c@tekito.com | Cさん |
「メールアドレス」によって「名前」が決定される(関数従属性がある)ので、以下のように分解する
| ID(A) | 名前(C) |
|---|---|
| 1 | Aさん |
| 2 | Bさん |
| 3 | Cさん |
| ID(A) | メールアドレス(B) |
|---|---|
| 1 | a@tekito.com |
| 2 | b@tekito.com |
| 3 | c@tekito.com |
こうやってまとめてみると、確かに第三正規化、ヘタしたら第二正規化までで実務には十分だと分かるね。